The other day, four Québécois gentlemen put out an arxiv preprint about one of my favorite topics*—algorithms for network epidemiology. In this blog post, I will try to lure you into: (1) Reading their manuscript. (2) Thinking about network-epi algorithm design. (3) Using my code for SIR (and theirs for SIS).
*As a problem-solving exercise, that is. I have to admit it is not the most pressing issue for mankind as of August 2018.
The problem is simple: Take a simple graph of just nodes and edges. Take a compartmental model of theoretical epidemiology. For example, the SIR or SIS models where a susceptible (S) node can be infected by an infectious (I) neighbor, and then become recovered (R) after some duration (that’s the SIR model) or S again (for SIS). Now the task is to sample the set of possible outbreaks with the correct probabilities and do it as fast as possible. Once you start thinking about how to do that, you will notice that the most uncomplicated approaches will do many things they don’t have to. This means, there are many ways to make the simulation quicker (and I think even the algorithms I mention here operate far from the theoretical optimum).
Chess players occasionally debate if their game is an art, sport, or science. Different players even seem to embrace various aspects out of these three, some seemingly going against all principles in flamboyant attempts to win like never seen before, some apparently executing their cerebral chess algorithms like machines. These three aspects do not usually come together in my research, but when I write my network-epidemiology simulation code, they do.
By this classification, the preprint by St-Onge et al. is science. They combine several ideas from the recent literature that, on the one hand, are systematic and methodological; on the other hand, not at all trivial. They split the nodes into those that might get infected soon, and those that cannot (so that one doesn’t have to care about updating the latter ones). (In my only algorithm paper, I also used that trick, but the rest of that algorithm was not my most glorious moment.) Maintaining such a division, of course, comes with book-keeping overhead, but according to the analysis, it will pay off for larger system sizes.
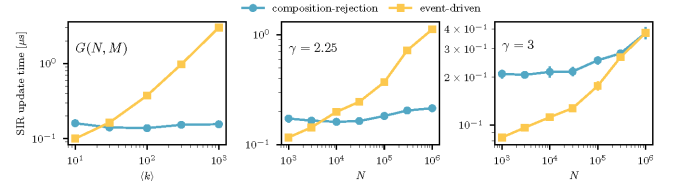
My own network SIR implementation has to go under the sports category. Most of the ideas are due to Joel Miller, although I didn’t have his code in front of me when I wrote it (and it is so simple that might have been invented independently by others). I (or instead, the competitive side of me) just want to have the fastest code. Of course, the first thing I did after reading the manuscript was to run the code myself. First, I tried to recreate the SIR section of Fig. 4, and indeed my code beat St-Onge et al. ’s composition rejection method for all cases (networks and parameter values) except the densest. In an email, Dr. St-Onge promised to tune his code further, so the race is on 😅. Still, if you care only about speed and not convenience (their code has excellent Python bindings and should be much easier to plug into your pipeline). My code should be best for most empirical and typical-sized model networks.

What about the arty algorithms? I’m sure the good is yet to come. When I think about this problem, there always seem to be some redundancies to be exploited just around the corner. I’d be surprised if there isn’t a beautiful, super-quick algorithm to be discovered. Ah, hang on . . it’s not really the same problem, but this might be art, and as such, I leave it for you to interpret.
Finally, if you’re interested in the SIS model, I do think the composition rejection is the fastest. The event-driven approach I use is just a bad idea when generations of the disease start mixing (as they could in any model that allows reinfections).
Absolutely finally, the joy of coming up with network epi algorithms is even higher for temporal networks. Time puts even more restrictions on the transmission trees, making the outbreak trees more similar to one another. This means that there are more redundancies to exploit and more room for algorithmic ingenuities.
Update Aug. 31: As promised, Dr. St-Onge managed to speed up his code quite a bit, and now it is faster than mine for many parameter values. He also gave me some tips for speeding it up further, so we’ll see how it ends (I don’t have time to work on that for a while tho).