I revised this post after comments from Urska Demsar, Travis Gibson, Des Higham, Carl Nordlund, Mason Porter, Max Schich, Jan Peter Schäfermeyer, Johan Ugander, Balazs Vedres, and Jean-Gabriel Young. Thanks!
Our field is interdisciplinary, and many smart people have been thinking about similar things. No wonder things get reinvented and rediscovered many times. I don’t think science is a competition to get good ideas first. On the other hand, who was the first to come up with this or that is a perfect conversation starter across disciplines . . I know people rooting for their field like a sports team.
Here is a list of some first appearances/applications of some big ideas. I restrict myself to:
- The pre-Watts-Strogatz era.
- Ideas that are in active use today (sorry Euler).
- Omitting networks only used to illustrate the connections between different items. (That could be a future blog post.)
- Omitting studies without empirical networks.
But please take it all with a grain of salt and lemme know what I forgot.
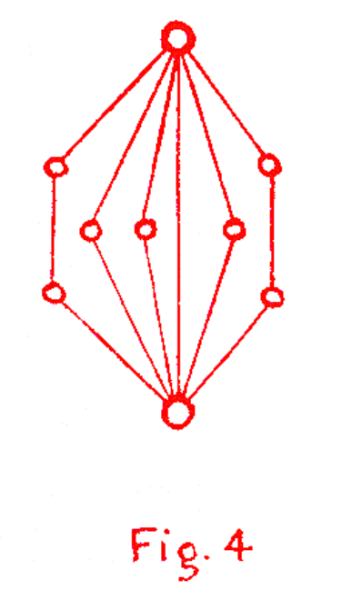
Network positions
…i.e., the idea that one can learn about the nodes in a network by how they are connected to the rest of the network. It is tricky to pinpoint who got the idea first. German sociologist/philosopher Georg Simmel described society as interconnected and overlapping social circles structured by social forces (see, e.g., his 1890 book chapter Über die Kreuzung socialer Kreise (The web of group-affiliations)). However, Simmel never gathered or analyzed actual data, and it is unclear if he envisioned actual empirical network analysis to uncover social structure. The first people to do that were Jacob Moreno and Helen Jennings in the early 1930s:
JL Moreno, 1932. Application of the group method to classification. National Committee on Prisons and Prison Labor, New York.
that I haven’t got my hands on it yet, but Linton Freeman writes the following about the figure above:
He characterized that image as showing “a group in which two dominating individuals are strongly united both directly and indirectly through other individuals.” Thus, Moreno viewed that picture as a display of both cohesiveness (“strongly united”) and social roles (“dominating individuals”).
Jennings was also involved in this work. Moreno’s son’s biography of Moreno mentions that Jennings did all the data collection and analysis in all of their network (sociogram) papers. It’s intriguing that network science also had an under-credited female pioneer, and tricky to find much information about her online. Moreno’s biography paints a picture of her as a brilliant but sad character “remembered in our family lore as a lonely person.”

Random graphs
…were also first studied by Helen Jennings and Jacob Moreno in
JL Moreno, HH Jennings, 1938. Statistics of social configurations. Sociometry, 1(3/4):342–374.
More specifically, they consider a model where n directed degrees per node were attached to random other nodes and studied the fraction of reciprocated links in their network data compared to the random model.
An honorable mention goes to Solomonoff and Rapoport that invented random graphs independently (and earlier than Erdős-Rényi or Edgar Gilbert):
R Solomonoff, A Rapoport, 1951. Connectivity of random nets. Bull. Math. Biophysics 13:107–117.
This paper derives the phase transition of the giant component and builds a mathematical theory (that Moreno and Jennings never did). Of course, Erdős and Rényi made a yet more in-depth analysis than Solomonoff and Rapoport. Rapoport also had a paper from 1948 studying random configurations where nodes have only one outgoing link attaching to a random other node.
A Rapoport, 1948. Cycle distributions in random nets. Bull. Math. Biophysics 10(3):145–157.
Network structure
= the way a network differs from a random null model. This must also be attributed to Moreno & Jennings (their 1938 paper above uses random graphs as null models to define the structure, e.g., the tendency for social ties to be reciprocated).
Degree distributions
Also Helen Jennings in:
H Jennings, 1937. Structure of leadership: Development and sphere of influence. Sociometry 1:99–147.
Random graphs with given degrees
(I.e., more or less the configuration model). They were around before Molloy and Reed’s work on the giant component. As so often happens, this invention seems to have occurred in parallel (probably to the sound of Jailhouse Rock and Great Balls of Fire)
D Gale, 1957. A theorem on flows in networks. Pacific J. Math. 7(2):1073–1082.
…all effectively discusses the configuration model (without multiedges). The last two papers are similar (talking about the existence of graphs with given degree sequences—the “graphicality”).
The idea of describing such graphs by matching stubs, and the name “configuration model,” comes from Béla Bollobás’s AFAIK most cited paper:
Rewiring edges for network null models
This is related to the previous item because early netsci papers typically constructed random networks with the same degree sequence as an empirical one by randomly rewiring them. The first such paper I know of is
…but it is for bipartite networks.
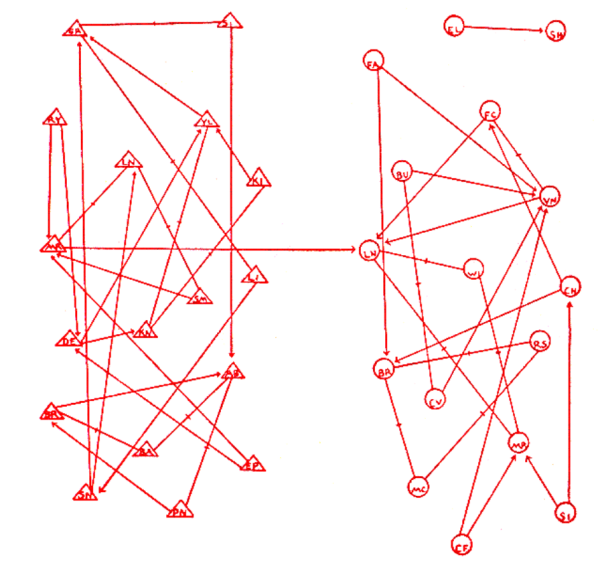
Community structure
This is tricky. First, even Moreno and Jennings talked about cohesive groups in the context of their study of school children. But they never gave a formal definition (let alone proposed an algorithm to detect them). Even earlier, in the context of analyzing voting patterns, Rice proposed a method of identifying political blocs by examining the network of agreements/disagreements (but no network visualization 😦 ).
Community detection, as we know it today, entered the stage after conceptually very similar analysis methods.
The first such method I’m aware of is hierarchical decomposition—defined via the algorithms HIDECS 1, 2, and 3—by mathematician / architect / design theorist Christopher Alexander in the early 1960s.
The second method is graph partitioning—splitting a graph into two communities. Just repeating graph partitioning is a community detection method—not necessarily excellent, but probably better than the worst (and actually what karate-club Zachary did in his karate-club paper). The starting point of graph partitioning algorithms was perhaps:
The problem itself seems to have been around some time by then since it was also the topic of Kernighan’s Ph.D. thesis.
The third method akin to community structure is hierarchical clustering. By this approach, one splits (or joins) a group of stuff based on some connection strength between pairs of them. It was, for many years, not directly applied to finding clusters of graphs. The first such algorithm was CONCOR:
That came from the interest in block models of social networks—also covering other mesoscopic structures than community structure—pioneered by Harrison White and colleagues.
Eigenvector centrality
Writing blog posts is the best way of learning! A reader kindly pointed me to an 1895 paper about scoring chess tournaments by eigenvector centrality
E Landau, 1895. Zur relativen Wertbemessung der Turnierresultate. Deutsches Wochenschach 11:366–369.
Note that this was before the Perron-Frobenius theorem. Well, it’s also earlier than the idea that studying a graph of relations could say something about a system was put into print.
Distance-based centrality measures
These were described in abstract terms by German/American psychologist Kurt Lewin and coworkers. In 1948, Alex Bavelas tried to translate these into a mathematical language.
A Bavelas, 1948. A mathematical model for group structures. Applied Anthropology 7(3):16–30.
Bavelas writes:
The central region of a structure is the class of all cells with the smallest [longest distance] to be found in the structure.
I.e., the inverse eccentricity. It also mentions the importance of being central in rumor propagation.

Network motifs
From this recent paper (Network motifs and their origins, by Stone, Simberloff, Artzy-Randrup), which I read just a few days ago (that prompted me to write this blog post), I learned that network motifs were first proposed in the Ph.D. thesis of Lewis Stone, 1988. Although I have to say precursors like
are very similar in spirit (even though their method is restricted to triangle counts in somewhat restricted sets of graphs).
Node importance via the impact of their deletion
This is an idea that has been (re)invented, maybe more than any other. To evaluate the importance of a node by checking what happens to the system if it is deleted. To the best of my knowledge, the first paper with this idea is
(A top journal in the field of management science! Not the usual place to look for groundbreaking network science (anymore).) Where they look at what happens to maximal flows when nodes are deleted. The influence of the invention of the Ford–Fulkerson algorithm was immense in the 1970s (I already mentioned Zachary’s karate club paper inspired by the same max-flow/min-cut algorithm).
Correlating network structural measures with a quantity of interest
The first to do this fairly fundamental network science analysis that I know about was KJ Kansky in his Ph.D. thesis The structure of transportation networks. Kansky showed how the density of countries’ railroad networks predicted imports.
Measuring the network structure by information entropy
Nicolas Rashevsky and his entourage were obviously extremely creative and ahead of their time. It’s somewhat surprising they don’t feature more in this list, but the idea to measure the level of organization in networks by some kind of entropy was first proposed in:
Tuning the structure of a network and measuring the response of dynamics
Related to the previous topic, it seems like an obvious idea to measure the response of a quantity of interest to a property that could be tuned in a network model. I can imagine electrical engineers did it before, or geographers (often unsung heroes, pioneering many approaches of network/data science decades ago that still feel very fresh). The first paper that—to 95%—fits the description is by Martina Morris and Mirjam Kretzschmar:
It is 95%, not 100%, because they don’t generate the (temporal) networks explicitly and never measure the network structure netsci-style. They do it alongside the disease simulation and control the structure by imposing it in their generative model.
Coda
For the tongue-in-cheek competition between disciplines, I note that psychology, mathematics, and sociology are doing well in getting my mentions. More interesting, however, are the many cases of simultaneous inventions—like the three papers in 1957 all proposing the configuration model, or the 1975 publications of the defining works of graph partitioning and hierarchical clustering of networks. Judging from these observations, it is probably better to credit the ideas to the field rather than to individuals. I will (at least for today) forget my Einstein ambitions and feel right about being a shiny bolt in the vast machinery of science.
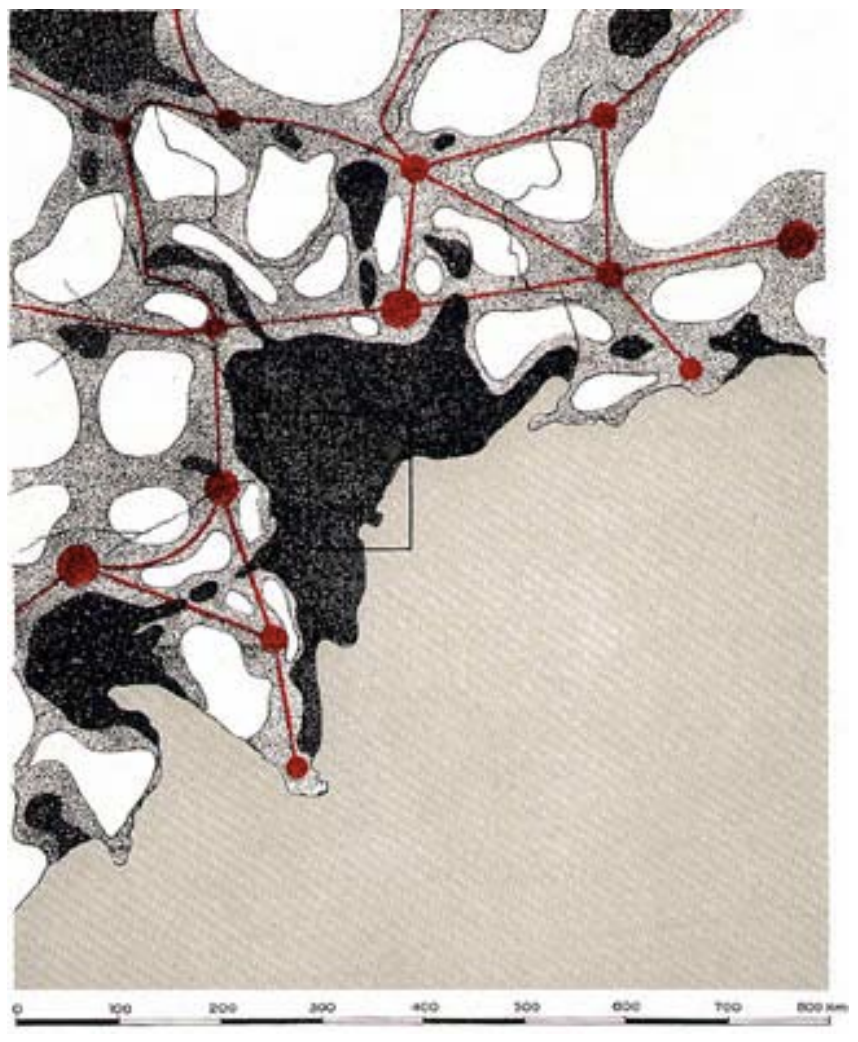
Postscriptum
I got several comments on this post, mentioning forgotten pioneering papers. E.g., works by geographers and urban planners (whom I respect very much (as any loyal reader of my blog/twitter posts would know)). I added a beautiful example of network arguments in geography above. This post is about the core ideas of network science (defined roughly as the science of people who feel at home at the NetSci conferences series). The legacy odf many of these early papers is not that they introduced ideas that still linger but that they broke new ground that eventually led to modern network science. For example
that points out how radically different directed acyclic graphs are from graphs with cycles and the impact of self-links. Also, the theory of transport networks had remarkably early papers, such as AN Tolstoy’s 1930 paper about minimizing the transportation costs in railway systems. Similarly, power engineering had methods to simplify circuit diagrams in the 1930s that, at least as a problem, feel similar to today’s network science.

Reblogged this on Systems Community of Inquiry.
LikeLike