In my and adjacent research fields, measures and methods and their names have complex and sometimes detrimental relationships. This is especially true when the names have a clear and relevant meaning in the vernacular. There are several related mechanisms for which I have only scanty evidence (hopefully to be supported further in the future):
- The colloquial meaning of the name influences the interpretation of the measure.
- Measures are grouped together because their names have a word in common.
- The inertia of language slows down the evolution of an idea.
The spirit of this post is not at all indignation for what science could have been. Maybe I’m too old for that. I rather feel a solemn resignation to the limitations of our language. There is not much we could or should do about it; other than be aware of the issue.
Efficiency
Once, I chatted with an economist, Dr. N.N., who declared himself largely unaware of network science, “except some years ago I did toy around with measuring efficiency for some of my data sets.” “Well, then you do know something,” I retorted, “because efficiency is usually not the first network measure to try.” At which point, the economist explained that the only research question he was interested in was how efficient his system was (and I dropped the discussion, not being in the mood for lecturing then . . but now I apparently am 😆).
For a connected graph, the average distance is a way of judging how tightly connected it is. Although it depends on many factors—the type of system being studied, the dynamics occurring on the network, the possible costs involved in maintaining it, the possible interventions, etc.—it is probably rarely capturing the everyday meaning of “efficient.” The most tightly connected graph is fully connected, but an airline network with flights between every pair of airports would be painfully inefficient in any economic sense.
If we persist with the idea that networks are worthy of the epithet “efficient” by the sole virtue of having short distances, we still run into problems if the network is not connected. Then the average distance is infinite and thus useless. Latora and Marchiori’s efficiency is the mathematically simplest way to give a non-trivial answer for disconnected networks. It measures the average inverse distance rather than the average distance (so node pairs of distinct components contribute with zero, rather than infinity, to the average). This, however, is a mix of the component-size statistics and the distances within components that is hard to have an intuitive feeling for—e.g., why would two cliques of half the nodes be valued equal to a star graph of all nodes?
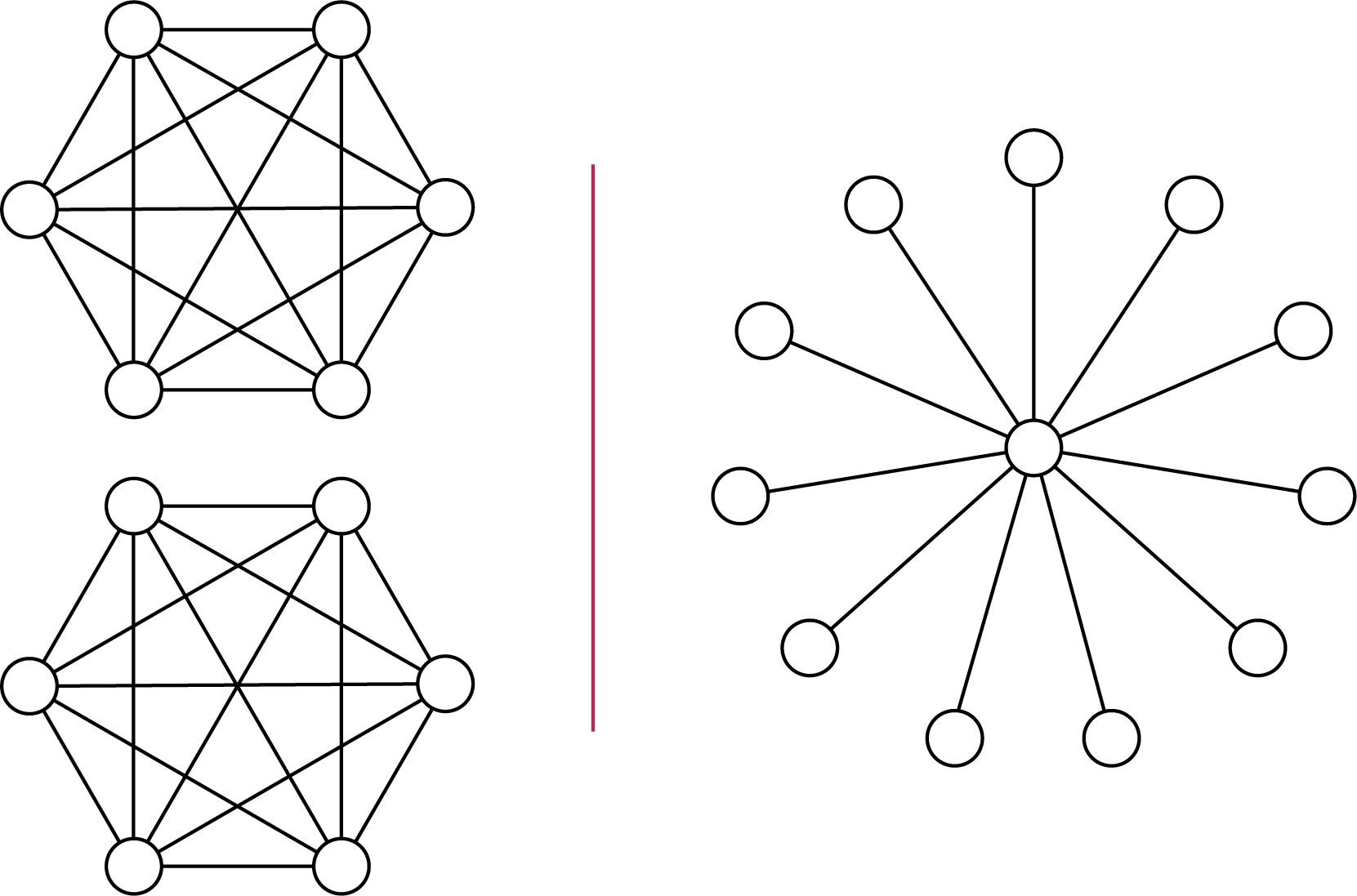
The bottom line is not that Latora and Marchiori’s efficiency is terrible—it isn’t and I use it myself—only that it most likely isn’t the closest measure network science has to offer to what Dr. N.N. had in mind. Furthermore, yes, he was lazy not to read up on all the literature, but there is a logic to it. It probably takes a lot less effort to motivate a measure called efficiency as a proxy for whatever economic efficiency he had in mind. Aptly named measures enable you to exploit the laziness of others.
Centrality
Linton Freeman’s seminal “Centrality in social networks – conceptual clarification” describes different centrality measures as capturing various aspects of the colloquial word. Degree, closeness, and betweenness centrality are prototypical examples of three such facets of “centrality.” With this protocol for deriving measures, the class inherits the ambiguities of a human language, English, which leads to three absurdities: First, should one then construct other classes when presenting network science in other languages (given that translations often can’t cover all nuances of a word)? Second, words can have different connotations for different people. Indeed not everyone would arrive at degree being an aspect of centrality (but it is easy to see how it comes out of social network analysis, where ego-centric networks are an essential concept). Third, wouldn’t one miss many important structural measures lying just out of reach for a mathematical formulation of the word?
Everything would be perfectly fine if we just thought of the different centralities in the literature as, simply, measures of different types of network positions. Not members of a class that does not* contain related concepts like vitality measures (impacts of deletion of nodes), controller nodes, etc. (*Maybe some authors would say they do, but probably not Freeman et al.) Finally, I do like Freeman’s approach. It feels as free as the general spirit of network science, whereas it is unclear what axiomatic definitions bring to the table. (Some rigor, you might say, but only the same rigor that allows thousands of definitions of the center of a triangle.)
Complexity
In complexity science, “complexity” could refer to the field as a whole but also to a multitude of specific measures and concepts for particular systems. Some authors allude to complexity measures being facets of an underlying, unifying organizational principle. Thus, being a grouping of measures for a very different reason than centrality measures. However, the set of measures called something with is so heterogeneous that it’s hard to imagine a profound, hidden principle behind them. I think that is one reason complexity scientists always return to the definition of complexity (more about that in this recent blog post). I also think this concern about creating and connecting measures to the existing body of measures with similar names holds science back.
Accessibility
In urban science, there is an incredible number of measures named “accessibility.” This situation is somewhat similar to that of “centrality” discussed above. It is a crucial term for describing places in cities, but one can interpret the colloquial word in many ways. Possibly, accessibility measures are more coherent than centrality measures, though.
Universality
“Universality” is a term that changed meaning, possibly because of its connotations of grandeur. (I hope to write more about this shortly.) Initially, universality was a relatively loose (i.e. far from a law) discovery in the physics of phase transitions, but later it became the battle call of physicists invading other disciplines. This, I say with tongue in cheek, remembering the following (funny and not entirely untrue) paragraph from Duncan Watts’s Six Degrees:
Physicists, it turns out, are almost perfectly suited to invading other people’s disciplines, being not only extremely clever but also generally much less fussy than most about the problems they choose to study. Physicists tend to see themselves as the lords of the academic jungle, loftily regarding their own methods as above the ken of anybody else and jealously guarding their own terrain. But their alter egos are closer to scavengers, happy to borrow ideas and techniques from anywhere if they seem like they might be useful, and delighted to stomp all over someone else’s problem. As irritating as this attitude can be to everybody else, the arrival of the physicists into a previously non-physics area of research often presages a period of great discovery and excitement. Mathematicians do the same thing occasionally, but no one descends with such fury and in so great a number as a pack of hungry physicists, adrenalized by the scent of a new problem.
Consequences
By now, I hope to have made the point that how measures are named has consequences for science. If you come up with a measure, there is a name that will optimize the attention it will get, and this name might not be the one that describes it most accurately. Like the moral issue of whether or not to state your data science results with the most captivating narrative, it is not necessarily the best to give the most accurate description. Pragmatically, if the dullness of your measure’s name makes it instantly forgotten, it will not serve the purpose of science, no matter how smart it is.
Idealism does not have much leeway in the world of science as we have created it. Even if the influence of language can hinder the best science, I don’t believe we should change anything too drastically. My only wish is that we occasionally remind ourselves of, and try to see through, these mental mechanisms.

2 thoughts on “How the names of quantities influence their interpretations”